In the rapidly evolving field of image processing, detecting scene changes in videos has emerged as a crucial area of research. The ability to accurately identify when one scene ends and another begins is vital for various applications, such as video editing, search algorithms, and analytical tools. With the explosion of content on social media, the demand for automated scene change detection has never been higher.
The Challenge
Scene transition detection involves identifying changes in context within a video, which can be marked by visual effects like fades, cuts, wipes, and dissolves. While humans can easily distinguish between different scenes, this task is quite challenging for computers, which perceive images and sounds at a binary level. Traditional methods, such as color histograms, motion vectors, and optical flow, have been used for this purpose, but deep learning approaches have recently gained prominence due to their ability to extract high-level features from scenes
Introducing FraSim: A Hybrid Approach
In our research, we developed a Convolutional Neural Network (CNN) model called FraSim, which we combined with a classical image processing method known as Structural Similarity (SSIM). This hybrid approach leverages the strengths of both deep learning and classical image processing to improve the accuracy of scene change detection.
Creating the Dataset
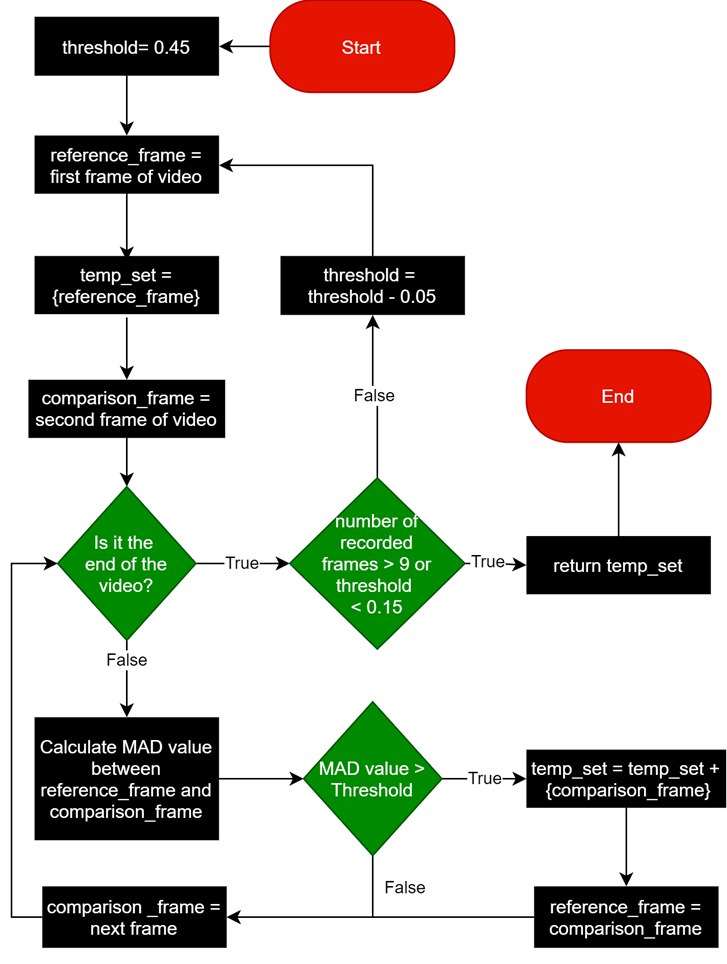
A robust dataset is essential for training any deep learning model. We created a comprehensive dataset by collecting movie scenes from the internet and enriching them with frames that mark transitions between scenes. This dataset is available in both grayscale and RGB formats and includes audio to provide additional context. To ensure that only the most notable frames were retained, we designed a unique algorithm to extract frames and associated audio during dataset creation. These frames were carefully categorized by scene and movie, resulting in a dataset that effectively supports our model training.
Self-Supervised Learning with Triplet Loss
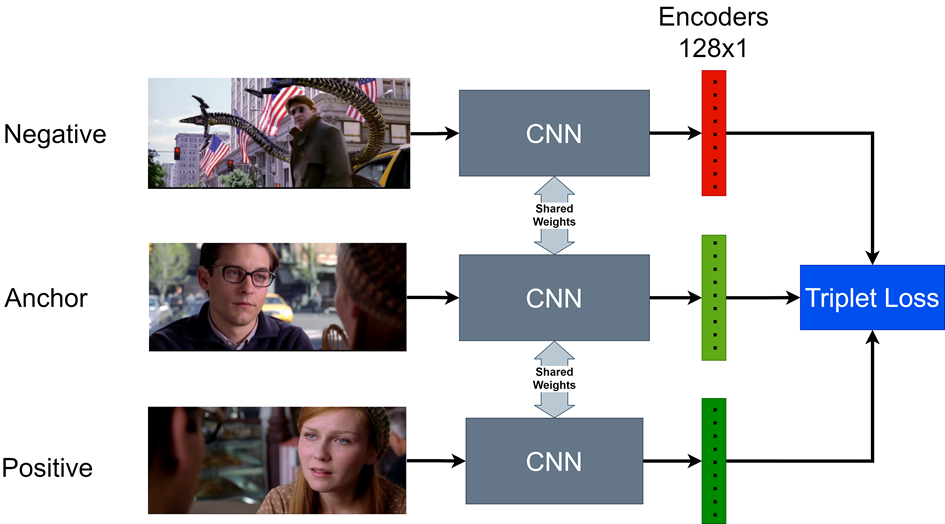
Training our model involved a self-supervised learning approach, where we used powerful techniques like Triplet Loss and Siamese Network architecture. The Triplet Loss function is particularly important as it optimizes the distance measurements between similar and dissimilar samples, enhancing the model’s ability to distinguish between different scenes.
The Architecture of FraSim
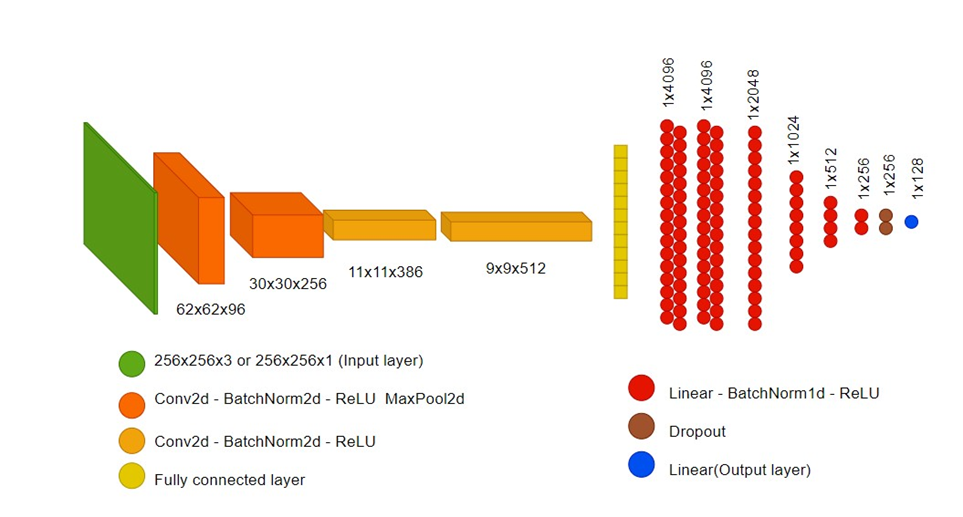
FraSim’s architecture is designed to encode scene information into a condensed latent space representation. This encoding is then used to determine the similarity between frames efficiently. The training process involves using an anchor (reference frame), a positive sample (a frame similar to the anchor), and a negative sample (a frame different from the anchor). By minimizing the distance between the anchor and the positive sample and maximizing the distance between the anchor and the negative sample, the model learns to differentiate between scenes effectively.
Combining Classical and Deep Learning Methods
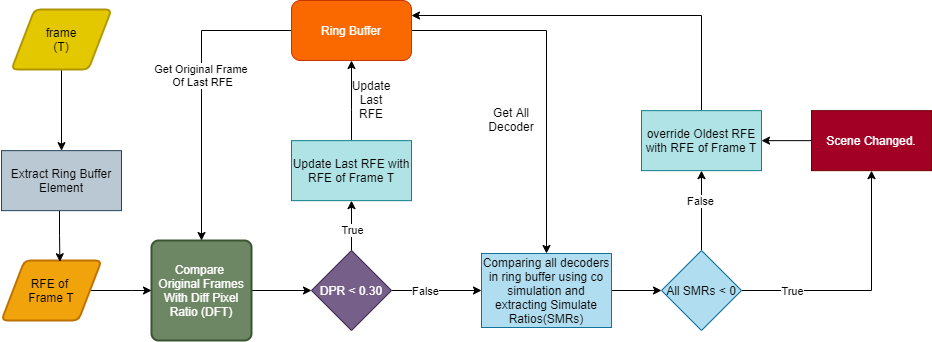
While deep learning models like FraSim are excellent at recognizing complex patterns, they can sometimes be sensitive to small pixel-based changes, which might not be noticeable to the human eye. Classical image processing methods, on the other hand, are robust against such minimal disturbances but may struggle with significant changes in image content. To address these challenges, we combined FraSim with SSIM. This hybrid approach utilizes the strengths of both methods, resulting in a more reliable and accurate scene change detection algorithm.
Impressive Results
Our research yielded impressive results, achieving an accuracy rate of up to 97.84% with the RGB dataset. This high accuracy demonstrates the potential of combining deep learning models with classical image processing techniques for scene transition detection. By introducing a new approach that encompasses both the structure of the training dataset and the architecture of the deep learning model, we have significantly contributed to the field of automatic video analysis.
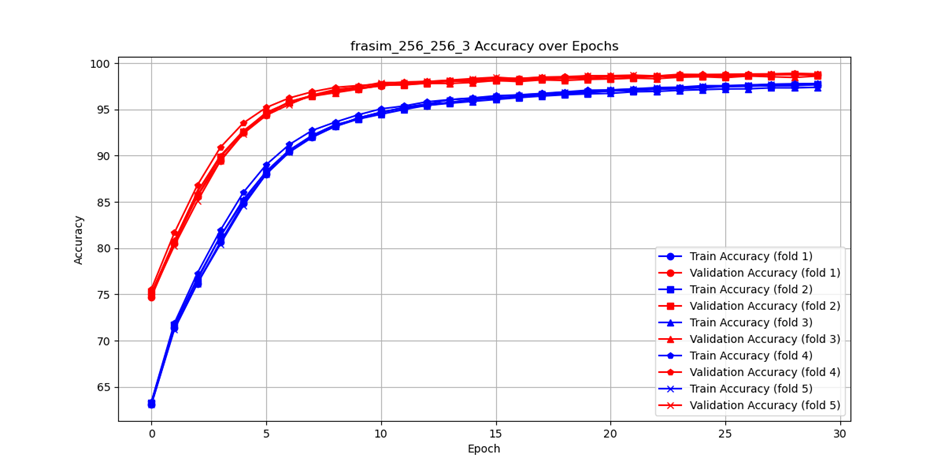
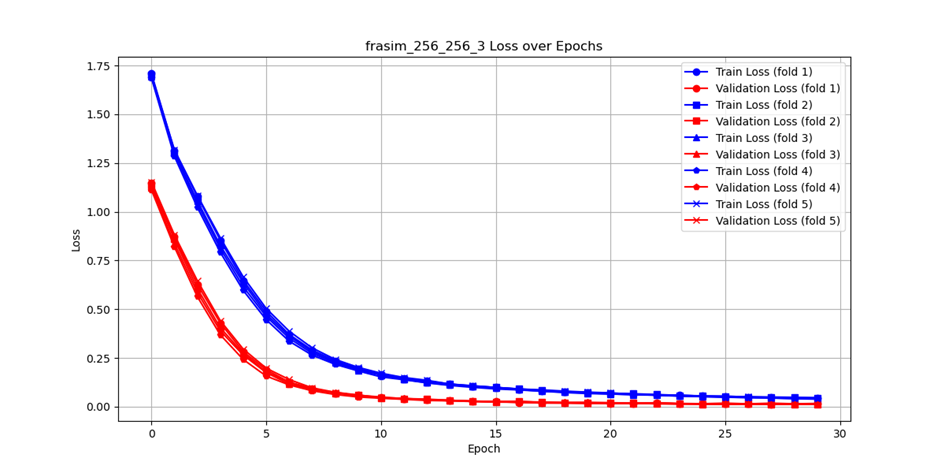
Conclusion
The integration of classical image processing techniques with intelligent systems like FraSim opens up new possibilities for video content analysis. This research not only highlights the effectiveness of hybrid approaches in detecting scene changes but also sets the stage for further innovations in automated video processing. As we continue to refine and expand our methodologies, we aim to enhance the real-time processing capabilities of our algorithms, making them even more versatile and powerful tools for various applications.
Examples:
Below are the outputs of the study. The top-left frames show the detected scene changes.



İlk Yorumu Siz Yapın